虚拟控件API
虚拟控件提供了针对界面上非结构化区域的自动化能力,结合图像识别(Image)、文字识别(OCR)及通用操作(Mouse / Keyboard)技术,可在未被标准自动化框架识别的场景下进行操作与验证。
| API 名称 | 描述 |
|---|---|
| all | 获取所有符合查找条件的虚拟控件。 |
| click | 点击虚拟控件区域内的指定位置。 |
| dblClick | 双击虚拟控件区域。 |
| exists | 判断虚拟控件是否存在。 |
| highlight | 高亮显示虚拟控件区域。 |
| moveMouse | 移动鼠标至虚拟控件内。 |
| pressKeys | 在虚拟控件中模拟键盘输入。 |
| rect | 获取虚拟控件的矩形区域信息。 |
| takeScreenshot | 截取虚拟控件的截图。 |
| wheel | 在虚拟控件内滚动鼠标滚轮。 |
| modelImage | 获取虚拟控件模型中保存的参考图像。 |
| modelProperties | 获取虚拟控件的模型属性。 |
| visualText | 通过 OCR 获取虚拟控件中的文字。 |
| clickVisualText | 点击虚拟控件中识别出的指定文字。 |
| textItems | 获取虚拟控件中分割的文字块子控件。 |
| checkImage | 对比虚拟控件与参考图像,验证视觉一致性。 |
虚拟控件的API大致可分为三类:
- 基础操作API:与传统控件操作类似的通用方法,用于点击、双击、存在性检查、高亮、鼠标移动、键盘输入、截图等。
- 文字识别(OCR)相关API:通过OCR识别虚拟控件中的文字,并可对识别出的文字进行点击操作。
- 图像比较API:通过图像比对技术检查虚拟控件当前界面与预期图像是否一致,以实现视觉验证。
类型定义
export interface Virtual {
// 基础操作
all(): Promise<IVirtual[]>;
click(x?: number, y?: number, mousekey?: number): Promise<void>;
dblClick(x?: number, y?: number, mousekey?: number): Promise<void>;
exists(seconds: number): Promise<boolean>;
highlight(duration?: number): Promise<void>;
moveMouse(x?: number, y?: number, seconds?: number): Promise<void>;
pressKeys(keys: string, opt?: PressKeysOptions | number): Promise<void>;
rect(): Promise<Rect>;
takeScreenshot(filePath?: string): Promise<string>;
wheel(value: number): Promise<void>;
modelImage(options?: {encoding: 'buffer' | 'base64'}): Promise<string | Buffer>;
modelProperties(all?: boolean): {[x: string]: any};
// OCR相关
visualText(options?: { whitespace: boolean }): Promise<string>;
clickVisualText(text: string, options?: {
cache: boolean,
x: number,
y: number,
button: number,
double: boolean,
down: boolean,
up: boolean }): Promise<void>;
textItems(options?: {expand?: number}): Promise<IVirtual[]>;
// 图像比较相关
checkImage(options?: CheckImageCompareOptions | string): Promise<void>;
}class Virtual:
# 基础操作
def all() -> List["Virtual"]
def click(x: Optional[int] = None, y: Optional[int] = None, mousekey: Optional[int] = None) -> None
def dblClick(x: Optional[int] = None, y: Optional[int] = None, mousekey: Optional[int] = None) -> None
def exists(seconds: int) -> bool
def highlight(duration: Optional[int] = None) -> None
def moveMouse(x: Optional[int] = None, y: Optional[int] = None, seconds: Optional[int] = None) -> None
def pressKeys(keys: str, opt: Union[PressKeysOptions, int] = None) -> None
def rect() -> Dict[str, int]
def takeScreenshot(filePath: Optional[str] = None) -> str
def wheel(value: int) -> None
def modelImage(options: Optional[Dict[str, str]] = {'encoding': 'base64'}) -> Union[str, bytes]
def modelProperties(all: Optional[bool] = False) -> Dict[str, Any]
# OCR相关
def visualText(options: Optional[Dict[str, bool]] = None) -> str
def clickVisualText(text: str, options: Optional[Dict[str, Union[bool, int]]] = None) -> None
def textItems(options: Optional[Dict[str, int]] = None) -> List[Virtual]
# 图像比较相关
def checkImage(options: Optional[any] = None) -> None
1. 基础操作API
这些方法的用法与 Qt 或 Windows 自动化的通用控件操作类似,可参考:
主要 API 如下:
all():获取所有符合当前虚拟控件定义的匹配结果,返回一个虚拟控件数组。click/dblClick:点击或双击虚拟控件内指定位置(坐标可选,不传则默认控件中心)。exists(seconds: number):在指定秒数内检查该虚拟控件是否存在。highlight(duration?: number):高亮显示该虚拟控件,辅助调试和定位。moveMouse(x?, y?, seconds?):将鼠标移动到虚拟控件内某点。pressKeys(keys, options?):在该控件中模拟键盘输入。rect():获取虚拟控件的矩形区域信息。takeScreenshot(filePath?):截取虚拟控件当前区域的屏幕图像。wheel(value):在虚拟控件区域内滚动鼠标滚轮。modelImage(options?):获取模型中为该虚拟控件保存的参考图像(Base64 或 Buffer)。modelProperties(all?: boolean):获取虚拟控件的模型属性(如对齐方式、矩形区域等)。
2. OCR相关API
当界面中的文字控件无法直接识别时,可通过OCR从虚拟控件中提取文本,并基于文本进行点击操作。更多OCR原理与详情请参考图像字符识别(OCR)。
visualText(options?: {whitespace: boolean})
将虚拟控件区域内的图像进行OCR识别,并返回识别出的文本字符串。
参数:
- options: (可选)识别选项
- whitespace:
boolean类型,指定是否识别空格,默认为false。
- whitespace:
返回值:
Promise<string>- 返回图片中的文本内容。
示例代码
let text = await model.getVirtual("Virtual1").visualText();
console.log('识别出的文本:', text);text = model.getVirtual("Virtual1").visualText()
print('识别出的文本:', text)clickVisualText(text: string, options?: {cache: boolean, x: number, y: number, button: number, double: boolean, down: boolean, up: boolean})
使用OCR在虚拟控件中查找指定文字,并对该文字区域进行点击。
参数:
- text:
string- 待查找的文字(如“打开”)。 - options: (可选)
object类型,文字点击时的操作选项。- cache:
boolean类型,设置是否缓存识别信息,默认为false。设置为true时,将复用上一次OCR结果,从而提高后续在同一控件内点击其他文字的响应速度。 - x:
number类型,点击位置相对于文字区域左上角的水平偏移量(像素)。0表示点击文字区域的水平中心位置。默认值为0。 - y:
number类型,点击位置相对于文字区域左上角的垂直偏移量(像素)。0表示点击文字区域的垂直中心位置。默认值为0。 - button:
number类型,表示要使用的鼠标按键,1为左键,2为右键,缺省值为1,即默认为左键。详细的键值列表见鼠标键枚举类。 - double:
boolean类型,设为true时,在指定目标画布位置双击鼠标按钮,缺省值为false。 - down:
boolean类型,在指定目标画布位置按下鼠标按钮(不释放),缺省值为false。 - up:
boolean类型,在指定目标画布位置释放鼠标按钮,缺省值为false。
- cache:
返回值:
- 不返回任何值的异步方法。
示例代码(复用OCR缓存信息)
以下示例演示了如何使用 cache 选项。以 Windows 自带的计算器为例,识别计算器的数字面板,并将其添加到模型中,对象名为 "Number pad"。
(async function () {
let numPad = model.getGeneric("Number pad").getVirtual();
await numPad.clickVisualText('4', { cache: true });
await numPad.clickVisualText('5', { cache: true });
await numPad.clickVisualText('6', { cache: true });
})();numPad = model.getGeneric("Number pad").getVirtual()
numPad.clickVisualText('4', { 'cache': True })
numPad.clickVisualText('5', { 'cache': True })
numPad.clickVisualText('6', { 'cache': True })示例代码(双击虚拟控件中文字的指定位置)
以下示例演示了如何使用x、y和double选项。在这个示例中,对象名为virtual的虚拟控件上文字ABC的可视区域将会被定位,随后鼠标将在该可视区域以左上角为原点、水平偏移30个像素点、垂直偏移20个像素点的位置进行双击操作。
model.getVirtual("virtual").clickVisualText("ABC", { x: 30, y: 20, double: true });model.getVirtual("virtual").clickVisualText("ABC", { 'x': 30, 'y': 20, 'double': True })示例代码(右键单击虚拟控件中的文字)
以下示例演示了如何使用x、y和button选项。在这个示例中,对象名为virtual的虚拟控件上文字XYZ的可视区域将会被定位,随后鼠标将在该可视区域中心位置进行右键单击操作。
model.getVirtual("virtual").clickVisualText("XYZ", { x: 0, y: 0, button: 2 });model.getVirtual("virtual").clickVisualText("XYZ", { 'x': 0, 'y': 0, 'button': 2 })异常处理
当在指定控件内未找到给定文字时,将抛出异常。可通过takeScreenshot()截屏和Ocr.getTextLocations()查看识别的文字块信息以进行诊断。
(async function () {
let numPad = model.getGeneric("Number pad").getVirtual();
let snapshot = await numPad.takeScreenshot();
let blocks = await Ocr.getTextLocations(snapshot);
console.log(JSON.stringify(blocks, null, 2))
})();numPad = model.getGeneric("Number pad").getVirtual()
snapshot = numPad.takeScreenshot()
blocks = Ocr.getTextLocations(snapshot)
print(json.dumps(blocks, indent=2))textItems(options?: { expand?: number })
获取当前虚拟控件内按文本块自动分割出的子虚拟控件列表。每个文本块会被包装成一个可直接操作的 Virtual 子对象(可执行 click()、highlight()、takeScreenshot() 等)。

参数
- options.expand(可选)
number类型。用于在识别出的文本块矩形区域外向四个方向扩展指定像素,默认值为2。适当外扩有助于在字体边缘模糊、抗锯齿、或渲染过细的场景下提高二次处理(如二次 OCR、截图、比对等)的准确性。提示:
expand取值过大可能导致相邻文本块的矩形重叠。若你的后续逻辑基于“第一个命中块”,请在相邻项较近的页面上使用较小的expand(如 2~4)。
返回值
- 返回子虚拟控件列表,每个子控件对应一个可视文本块。
示例:提取菜单文本并点击
// 将每个文本块外扩 4 像素,点击第一个“Settings”
const items = await model.getVirtual("menuBar").textItems({ expand: 4 });
for (const v of items) {
const text = await v.visualText(); // 读取该子块的文字
if (text.trim() === "Settings") {
await v.click(); // 命中区域更宽容
break;
}
}# 将每个文本块外扩 4 像素,点击第一个“Settings”
items = model.getVirtual("menuBar").textItems({ "expand": 4 })
for v in items:
text = v.visualText().strip() # 读取该子块的文字
if text == "Settings":
v.click() # 命中区域更宽容
break示例:改进截图精度
const items = await model.getVirtual("toolbar").textItems({ expand: 6 });
const saveBtn = items.find(async v => (await v.visualText()).trim() === "Save");
if (saveBtn) {
const snap = await saveBtn.takeScreenshot();
// 将 snap 与期望图像进行比对(略)
}items = model.getVirtual("toolbar").textItems({ "expand": 6 })
save_btn = None
for v in items:
if v.visualText().strip() == "Save":
save_btn = v
break
if save_btn:
snap_base64 = save_btn.takeScreenshot()
# 与期望图像进行比对(略)
3. 图像比较API
通过图像比较技术,checkImage 方法可以将虚拟控件的当前视觉表现与预期的参考图像进行比对。此方法是进行视觉验证的关键工具,常用于检测控件的状态变化、确保 UI 的视觉一致性。
在 CukeTest 环境中运行脚本时,如果 checkImage 方法因差异超出容忍度而失败,系统会自动将差异图像显示在运行输出面板中,并将其作为附件添加到最终的测试报告中,方便您直接查看和分析问题。
若希望在输出面板中显示差异图像缩略图,请确保已在运行设置中启用了
reportSteps。
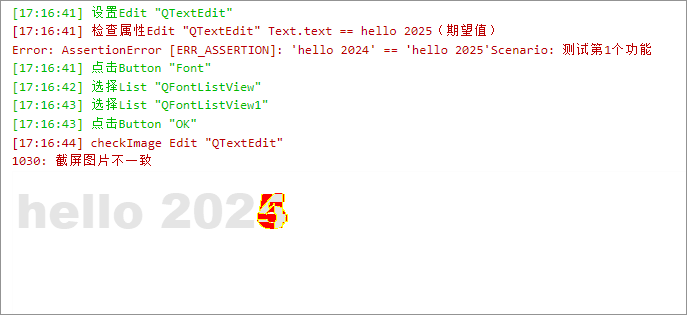
checkImage(options?: CheckImageCompareOptions | string)
此方法用于将目标控件的实时截图与一个指定的参考图像进行比对。如果两者之间的差异超出了预设的容忍阈值,方法将抛出异常,并在错误信息中包含一个视觉差异图(diffImage),以帮助您快速定位问题。
提示:该方法优先使用虚拟控件自身的截图进行比较;如果该虚拟控件没有独立的截图,则会从其父控件的截图中裁剪出对应的区域进行比对。
参考图像的指定方式及优先级:
checkImage 方法通过 options 参数提供了灵活的参考图像指定方式,优先级如下:
- Base64 数据:如果
options对象中提供了image属性(Base64 编码的字符串或 Node.jsBuffer),将优先使用该数据作为参考图像。 - 文件路径:
- 如果
options参数本身是一个字符串,它将被视为图像文件的路径。 - 如果
options是一个对象,且未提供image属性但提供了imagePath属性,则系统会加载该路径指定的图像文件作为参考。
- 如果
- 模型内置快照:如果
options参数被省略,或者是一个空对象,或者仅包含比较选项(如pixelPercentTolerance)而没有提供具体的图像源(image或imagePath),则默认使用在模型文件中为该控件预先保存的参考图像(快照)。
参数详解
类型:
CheckImageCompareOptions | string(可选)CheckImageCompareOptions配置对象: 当options参数为一个对象时,您可以配置以下属性来指定参考图像源并调整比较的精度和行为:图像源指定:
image?: string | Buffer: (可选) 提供 Base64 编码的图像数据(string类型)或 Node.js 的Buffer对象。如果提供此参数,控件的当前图像将与此图像数据进行比较。- 注意: 在 Python 环境中,仅支持传递 Base64 编码的字符串。
imagePath?: string: (可选) 提供图像文件的路径字符串。如果未提供image属性,但提供了此属性,则系统会加载并使用此路径指定的图像文件作为参考。
图像比较选项:
colorTolerance?: number: (可选)number类型,定义了在颜色匹配时允许的最大差异容忍度。默认值为0.1。数值越小,颜色匹配越严格。pixelPercentTolerance?: number: (可选)number类型,定义了允许的最大像素百分比差异容忍度。例如,默认值1表示最多允许1%的像素差异。pixelNumberTolerance?: number: (可选)number类型,定义了允许的像素数量差异容忍度。如果设置为0,则表示在像素数量上不允许任何差异(除非被pixelPercentTolerance覆盖)。ignoreExtraPart?: boolean: (可选)boolean类型,用于指定在比较时是否忽略其中一张图像多出来的部分。默认为false。
返回值:
Promise<void>: 不返回任何值的异步方法。如果图像比较失败,将抛出异常。该异常对象中包含一个diffImage字段,它是一个Buffer类型的 PNG 数据,表示两张图像的视觉差异。您可以使用try...catch语句捕获此异常,并将差异图保存为本地文件,便于调试和可视化对比。
使用示例
以下示例展示了 checkImage 方法的多种用法,假设 model.getVirtual("button_image") 返回一个虚拟控件对象:
// 示例准备:获取图像的 Base64 编码 (仅为演示,实际使用时按需获取)
let expect_image = await Image.fromFile("button1.png");
let image_data_base64 = await expect_image.getData({encoding: 'base64'});
// 1. 与 Base64 图像比较
await model.getVirtual("button_image").checkImage({ image: image_data_base64 });
// 2. 与 Base64 图像比较,并自定义容忍度
await model.getVirtual("button_image").checkImage({ image: image_data_base64, pixelPercentTolerance: 10 });
// 3. 与文件路径图像比较 (直接传递路径字符串)
await model.getVirtual("button_image").checkImage("button1.png");
// 4. 与文件路径图像比较 (通过 options.imagePath)
await model.getVirtual("button_image").checkImage({ imagePath: "button1.png" });
// 5. 与文件路径图像比较,并自定义容忍度
await model.getVirtual("button_image").checkImage({ imagePath: "button1-error.png", pixelPercentTolerance: 5, colorTolerance: 0.05 });
// 6. 与模型内置快照比较,并自定义容忍度
await model.getVirtual("button_image").checkImage({ pixelPercentTolerance: 0.5, colorTolerance: 0.05 });
// 7. 与模型内置快照比较 (使用默认容忍度)
await model.getVirtual("button_image").checkImage();
// 将差异图片添加到报告中
try {
await model.getButton("Underline").checkImage();
} catch (error){
this.attach(error.diffImage,"image/png")
}import base64 # Python 示例需要导入 base64 模块
# 示例准备:获取图像的 Base64 编码
base64_value = None
with open("button1.png", "rb") as f:
base64_value = base64.b64encode(f.read()).decode("utf-8")
# 1. 与 Base64 图像比较
model.getVirtual("button_image").checkImage({ 'image': base64_value })
# 2. 与 Base64 图像比较,并自定义容忍度
model.getVirtual("button_image").checkImage({ 'image': base64_value, 'pixelPercentTolerance': 10 })
# 3. 与文件路径图像比较 (直接传递路径字符串)
model.getVirtual("button_image").checkImage("button1.png")
# 4. 与文件路径图像比较 (通过 options['imagePath'])
model.getVirtual("button_image").checkImage({ 'imagePath': "button1.png" })
# 5. 与文件路径图像比较,并自定义容忍度
model.getVirtual("button_image").checkImage({ 'imagePath': "button1-error.png", 'pixelPercentTolerance': 5, 'colorTolerance': 0.05 })
# 6. 与模型内置快照比较,并自定义容忍度
model.getVirtual("button_image").checkImage({ 'pixelPercentTolerance': 0.5, 'colorTolerance': 0.05 })
# 7. 与模型内置快照比较 (使用默认容忍度)
model.getVirtual("button_image").checkImage()
# 将差异图片保存到本地
try:
model.getButton("Underline").checkImage()
except Exception as e:
with open("diff.png", "wb") as f:
f.write(e.diffImage)在上述示例中,若 button_image 控件的当前视觉表现与指定的参考图像(无论是 Base64 数据、文件,还是内部快照)的差异超出了设定的容忍度(例如 colorTolerance 或 pixelPercentTolerance),checkImage 方法将抛出错误,指示测试失败。