图像字符识别(OCR)
光学字符识别(OCR)是一项强大的技术,它可以将图像中的文字内容提取为可编辑的文本。在自动化测试和应用程序开发中,OCR技术可以帮助识别并验证图像或控件中的文字内容,即使这些控件并不直接支持文字提取功能。通过使用OCR库,你可以对内存中的图片、文件中的图片,甚至是从应用程序控件截图中提取文字,实现更广泛的自动化测试和数据处理。
控件上的OCR方法
visualText方法
下列的控件支持visualText方法:
visualText方法的函数方法如下:
visualText(): Promise<string>;def visualText(self, options: Optional[OcrOptions]=None) -> "str":详细说明,请参见visualText方法
clickVisualText方法
clickVisualText方法只适用于虚拟控件。此方法使用OCR在虚拟控件快照中查找指定的文本,然后点击对应的文本位置。
clickVisualText(text: string, options?: ClickVisualTextOptions): Promise<void>;def clickVisualText(self, text: str, options: Optional[ClickVisualTextOptions]=None) -> "None":有关详细文档,请参见clickVisualText方法
模型管理器中的OCR
在模型管理器中,你可以为包含可视文字的控件部分创建虚拟控件,然后在这些虚拟控件上调用 visualText 方法。你可以在模型管理器中测试 visualText 方法。请注意以下事项:
- 测试时,确保控件区域未被其他窗口覆盖。
- 模型管理器加载的OCR识别库与界面语言相关。即英文界面会加载英文语言训练库,中文界面会加载中文库。
如果在方法测试中想去掉识别后文字的空格,可以传递参数 {whitespace: false},如下图所示: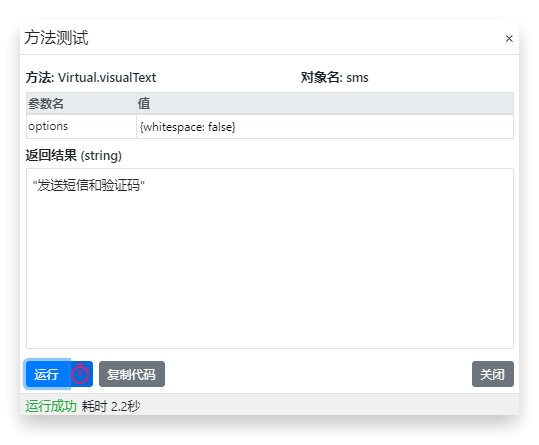
例如,在Windows控件 Menu 上创建 Top One的虚拟控件,然后调用 visualText 方法,如下图所示:
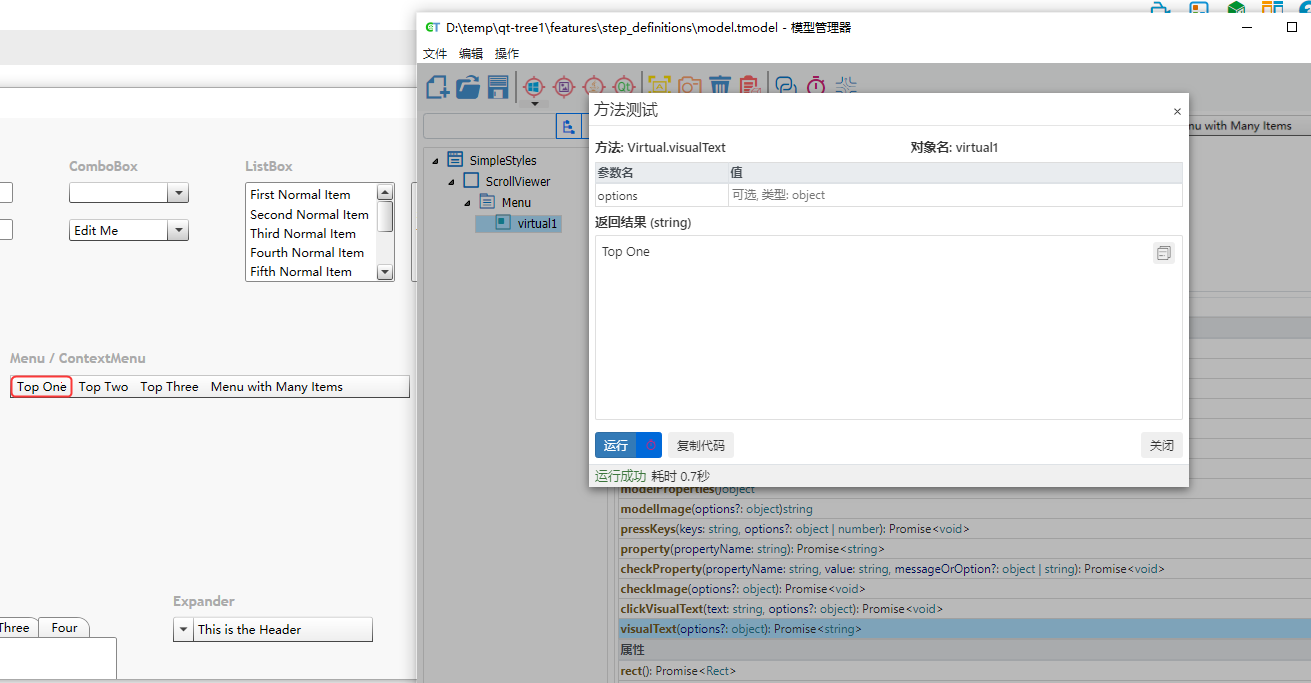
了解更多关于虚拟控件的信息,请参考虚拟控件
OCR库函数
你可以直接使用leanpro.visual下的OCR类,对内存中的图片或图片文件进行识别。以下是OCR库的定义和使用示例:
class Ocr {
public static getVisualText(imageData: Buffer | string, options?: OcrOptions): Promise<string>;
public static getVisualTextFromFile(filePath: string, options?: OcrOptions): Promise<string>;
public static getTextLocations(imageData: Buffer | string): Promise<TextBlock[][]>;
public static getTextLocation(imageData: Buffer | string, text: string): Promise<Rect>
}class Ocr:
def getVisualText(imageData: Union[bytes, str], options: Optional[Dict]) -> str
def getVisualTextFromFile(filePath: str, options: Optional[Dict]) -> str
def getTextLocations(imageData: Union[bytes, str]) -> List[List['TextBlock']]
def getTextLocation(imageData: Union[bytes, str], text: str) -> 'Rect'方法和使用示例
getVisualText(imageData: Buffer | string, options?: OcrOptions): Promise<string>
传入图片内容的Buffer,或base64编码的字符串,对图片进行识别并返回识别出的文字。
let screenshot = await model.getVirtual("virtual").takeScreenshot();
let visualText = await Ocr.getVisualText(screenshot);
console.log(`text is ${visualText}`);with open('../support/demo.png', 'rb') as f:
image_data = f.read()
visual_text = Auto.visual.ocr.getVisualText(image_data)
print(visual_text)getVisualTextFromFile(filePath: string, options?: OcrOptions): Promise<string>
传入图片文件的路径,对图片进行文字识别并返回识别出的文字。
let textPic = await Ocr.getVisualTextFromFile('../support/demo.png');
console.log(`text is ${textPic}`);visual_text_from_file = Auto.visual.ocr.getVisualTextFromFile('../support/demo.png')
print(visual_text_from_file)getTextLocations(imageData: Buffer | string): Promise<TextBlock[][]>
传入图片内容的Buffer或base64编码的字符串,对图片进行识别并返回识别的文字和位置。文字和位置以词为单位,返回包含TextBlock结构的二维数组,每个一维数组代表一行文字。
interface TextBlock {
text: string;
boundingRect: {
left: number,
top: number,
width: number,
height: number
}
}使用示例如下:
let imageData = fs.readFileSync('../support/demo.png');
let blocks = await Ocr.getTextLocations(imageData);
const block1 = blocks[0][0];
const block2 = blocks[1][0];
assert.equal(block1.text, 'HughesBill');
assert.equal(block1.boundingRect.left, 4, "计算图片文字左边值错误");
assert.equal(block1.boundingRect.top, 9, "计算图片上边值错误");
assert.equal(block2.text, 'HoyleTaylor');
assert.equal(block2.boundingRect.left, 4, "计算图片文字左边值错误");
assert.equal(block2.boundingRect.top, 39, "计算图片上边值错误");with open('../support/demo.png', 'rb') as f:
image_data = f.read()
blocks = Auto.visual.ocr.getTextLocations(image_data)
block1 = blocks[0][0]
block2 = blocks[1][0]
assert block1['text'] == 'HughesBill'
assert block1['boundingRect']['left'] == 4, "计算图片文字左边值错误"
assert block1['boundingRect']['top'] == 9, "计算图片上边值错误"
assert block2['text'] == 'HoyleTaylor'
assert block2['boundingRect']['left'] == 4, "计算图片文字左边值错误"
assert block2['boundingRect']['top'] == 39, "计算图片上边值错误"getTextLocation(imageData: Buffer | string, text: string): Promise<Rect>
传入图片内容的Buffer或base64编码的字符串,以及需要查找的文字,返回该文字在图片中的位置的Rect对象。如果不存在,则返回null。
其中:
- imageData: 图片内容的Buffer,或base64编码的字符串
- text:需要查找的文字,需是图片中存在的连续文字,且在同一行
let imageData = fs.readFileSync(fullpath);
let block = await Ocr.getTextLocation(imageData, 'HoyleTaylor');
let x = block.left;
let y = block.top;
assert.equal(x, 4, "计算图片文字左边值错误");
assert.equal(y, 39, "计算图片上边值错误");with open('../support/demo.png', 'rb') as f:
image_data = f.read()
block = Auto.visual.ocr.getTextLocation(image_data, 'HoyleTaylor')
x = block['left']
y = block['top']
assert x == 4, "计算图片文字左边值错误"
assert y == 39, "计算图片上边值错误"其它控件的OCR支持
虽然并非所有控件对象都直接支持OCR文字识别,但你可以通过以下步骤实现对任意控件的文字识别:
- 在控件上调用
takeScreenshot方法获取快照图片。 - 使用
Ocr.getVisualText方法识别该图片上的文字。
下面是一个示例代码:
const { Ocr, OcrLanguage } = require('leanpro.visual');
(async () => {
// 获取按钮的截图
let image = await model.getButton("Clear entry").takeScreenshot();
// 对截图进行OCR识别
let text = await Ocr.getVisualText(image);
console.log(text);
})();在这个例子中,我们从一个按钮控件获取图片,并将图片上的文字识别出来并打印到控制台。通过这种方式,你可以对任何控件的文字内容进行OCR识别,无论该控件是否直接支持OCR。
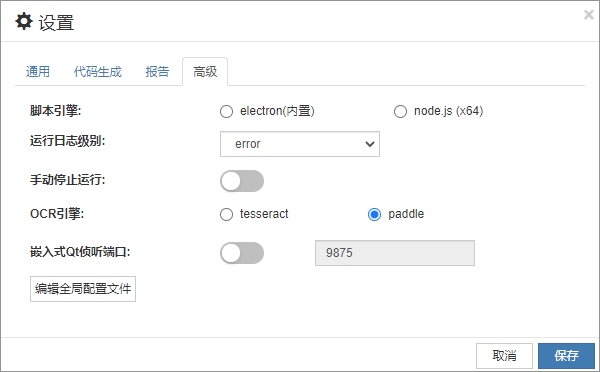
如何切换OCR引擎
在CukeTest中,您可以选择使用两种不同的OCR引擎:tesseract和paddle。通过切换单选按钮,您可以手动选择使用其中一个OCR引擎来进行文本识别。打开CukeTest界面,在“设置”->“高级”中的“OCR引擎”项目下点击标有tesseract或paddle的单选按钮,再点击“保存”键,即可完成OCR引擎的切换。